前言
网络安全实验居然有k8s,可惜要去实习了,所以提前了解一下
k8s结构
一个K8S系统,通常称为一个K8S集群(Cluster)。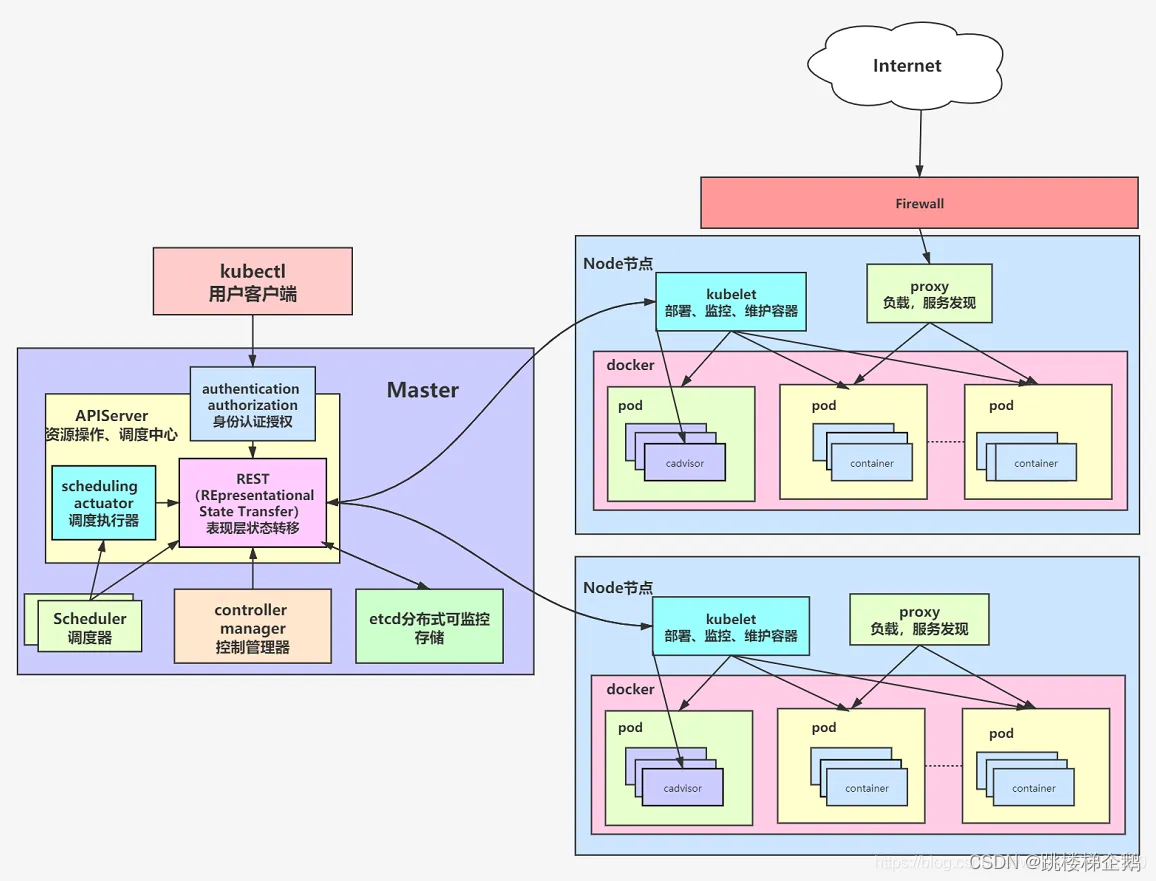
这个集群主要包括两个部分:
一个Master节点(负责管理和控制):包括API Server、Scheduler、Controller manager、etcd。
API Server是整个系统的对外接口,供客户端和其它组件调用,相当于“营业厅”。
Scheduler负责对集群内部的资源进行调度,相当于“调度室”。
Controller manager负责管理控制器,相当于“大总管”。
一群Node节点(具体的主机容器): 包含Docker、kubelet、kube-proxy、Fluentd、kube-dns(可选),还有就是Pod
Docker,创建容器的
Pod(Kubernetes最基本的操作单元)
Kubelet,主要负责监视指派到它所在Node上的Pod,包括创建、修改、监控、删除等。
Kube-proxy,主要负责为Pod对象提供代理。
Fluentd,主要负责日志收集、存储与查询。
kubectl
kubectl是Kubernetes的命令行工具,用于与Kubernetes集群进行交互
k8s-Pod(豆荚)

一个Pod代表着集群中运行的一个进程,一个Pod有一个或多个容器组成,Pod中容器共享存储和网络,如nginx+web服务+mysql就是一个pod
获取 Pod 的信息
1 | kubectl get namespace |
命名空间
默认情况下,k8s内部的namespace可以相互访问
1 | #显示所以命名空间 |
Pod 控制器
Pod 控制器又被称为工作负载,是用于实现管理pod的中间层,Pod 控制器包括 ReplicaSet、Deployment、StatefulSet 和 DaemonSet 等。这些控制器提供了对 Pod 的声明性定义和自动化管理,确保集群中的 Pod 始终处于所需的状态
Deployment
ReplicaSet(RS):代用户创建指定数量的pod副本,确保pod副本数量符合预期状态(负载均衡),并且支持滚动式自动扩容和缩容功能。
Deployment:通过管理ReplicaSet来间接管理Pod,用于管理无状态应用。支持滚动更新(滚动更新允许在不中断服务的情况下逐步更新应用程序)和版本回滚,还提供声明式配置。
1 | kubectl apply -f app.yaml #部署应用,没加-n或者配置文件没有namespace就是默认 |
Horizontal Pod Autoscaler(HPA)
上面的Deployment已经写死了副本数量,有没有一种方法可以根据访问流量自动调整pod副本数量使其符合预期状态,这就是HorizontalPodAutoscaler的作用,此处暂时不演示
StatefulSet
StatefulSet 是用来管理有状态的应用。
前面我们部署的应用,它只是处理 HTTP 请求,本身不生产数据(日志除外),不需要记住状态的,可以随意扩充实例,实例之间是无关的,启动的顺序不固定,Pod 的名字、IP 地址、域名也都是完全随机的
而像数据库、消息队列、缓存系统等 这类有状态的,这些节点的启动和停止需要遵循严格的顺序,重启时都需要挂载原来的数据卷
DaemonSet(DS)
DaemonSet 用于确保集群中的每一个节点(如果主节点没有污点,也会调度到主节点上)只运行特定的pod副本,通常用于日志收集、节点监控等场景。它的服务是无状态的。
Taint
污点可以用来避免Pod被分配到不合适的节点上,有三种模式
PreferNoschedule:表示k8s将尽量避免将Pod调度到具有该污点的Node上
NoSchedule:表示k8s将不会将Pod调度到具有该污点的Node上
NoExecute:表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod驱逐出去
(k8s从1.6开始,不会再将DaemonSet调度到主节点上。由于主节点上有node-role.kubernetes.io/master及NoSchedule污点)
1 | kubectl taint nodes <node-name> key=value:taint-effect #设置污点 |
所以如果某个节点有污点,是不会创建ds的
Tolerations
设置了污点的Node将根据taint的effect : Noschedule, PreferNoschedule, NoExecute和Pod之间产生互斥的关系, Pod将在一定程度上不会被调度到Node上。但我们可以在Pod上设置容忍(Tolerations) ,意思是设置了容忍的Pod
job
Job,主要用于负责批量处理短暂的一次性任务。当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量,当成功结束的pod达到指定的数量时,Job将完成执行
1 | kubectl get jobs -A |
Service
Service 把一类Pods上的应用程序抽象成服务,为一组 Pod 提供流量路由,允许 Kubernetes 中的 Pod 死亡和复制,而不会影响应用,使用户感觉不到变化
Service的三种主要形式
1 | kubectl get svc #查看服务 |
- ClusterIP: 仅仅使用一个集群内部的IP地址 - 这是默认值。选择这个值意味着你只想这个服务在集群内部才可以被访问到。
- NodePort: NodePort Service 是在 ClusterIP Service 的基础上,为 Service 在集群所有 Node 节点上绑定一个端口,外部客户端通过nodeIP:nodePort就可以访问服务。暴露的端口号范围为 30000-32767。
- LoadBalancer: 在使用一个集群内部IP地址和在NodePort上开放一个服务之外,向云提供商申请一个负载均衡器,会让流量转发到这个在每个节点上以:NodePort的形式开放的服务上
Service 自己会有一个域名,格式是对象名. 名字空间
存储(volumes)
数据持久化
hostPath 挂载:把节点上的一个目录直接挂载到 Pod
pv挂载:在pod中定义一个存储卷(该存储卷类型为pvc),定义的时候直接指定大小,**Persistent Volume Claim (PVC)必须与对应的Persistent Volume (PV)**建立关系,pvc会根据定义去pv申请,而pv是由存储空间创建出来的。pv和pvc是k8s抽象出来的一种存储资源
基于动态storageclass挂载:StorageClass是一个存储类,通过创建StorageClass可以动态生成一个存储卷,供k8s用户使用。使用StorageClass可以根据PVC动态的创建PV,减少管理员手工创建PV的工作
配置信息
ConfigMap 和 Secret 都是 Kubernetes 中用于存储和管理配置信息的资源对象,ConfigMap 适用于存储非敏感数据,而 Secret 则适用于存储敏感数据
1 | kubectl create configmap example-config --from-literal=database_url=mysql://localhost:3306 --from-literal=api_key=abc123 |
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 这样的信息可能会被放在 Pod 规约中或者镜像中。 使用 Secret 意味着你不需要在应用程序代码中包含机密数据。
1 | kubectl create secret generic example-secret --from-literal=username=myusername --from-literal=password=mypassword |
网络
Kubernetes 使用平面网络架构。默认情况下,集群内的命名空间没有任何网络安全限制。
访问权限控制(RBAC)
主体(subject):
User:用户
Group:用户组
ServiceAccount:服务账号
角色:
Role:授权特定命名空间的访问权限
ClusterRole:授权所有命名空间的访问权限
角色绑定:
RoleBinding:将角色绑定到主体(即subject)
ClusterRoleBinding:将集群角色绑定到主体
实战
于之前写内网渗透文章结构不同,以下方法并没有顺序性,比如如果你拿下k8s当然可以node节点内横向,这样写只是为了好区分,具体实战根据实际情况判断
检测是否是K8s环境
1 | df -T #存在 /run/secrets/kubernetes.io,确认是 K8s 环境 |
本地权限提升
CVE-2021-22555
其他见之前写的内网渗透
node节点内横向
docker 逃逸
自动扫描逃逸漏洞
./cdk_linux_amd64 evaluate
见之前写的 Docker 实践
K8S节点集群内横向
敏感信息泄露
1 | kubectl auth can-i --list #我们具有的权限 |
其他还有 k8s configfile 泄露,云账号AK泄露
API Server未授权(8080,6443)+污点横向
1 | cat /run/secrets/kubernetes.io/serviceaccount/token |