前言
最近web学习有点迷茫,就像学习一下新鲜的知识,简单学习了一下ctf里面的re,个人感觉还是比较好学的,不是很底层,向程序,特别是神器ida,一键转c,让我找到代码审计的感觉。偏知识底层的我就补到其他文章里,这里只记录一些应用的东西
可执行文件格式
ELF文件是编译完毕后经过链接,可以直接运行的文件
ELF文件包含了完整的ELF文件头和段表、字符串表、符号表以及其他表
ELF文件是一系列代码、数据、表按照一定规则打包起来的数据包
elf文件的节(section)会被映射进内存中的段(segment)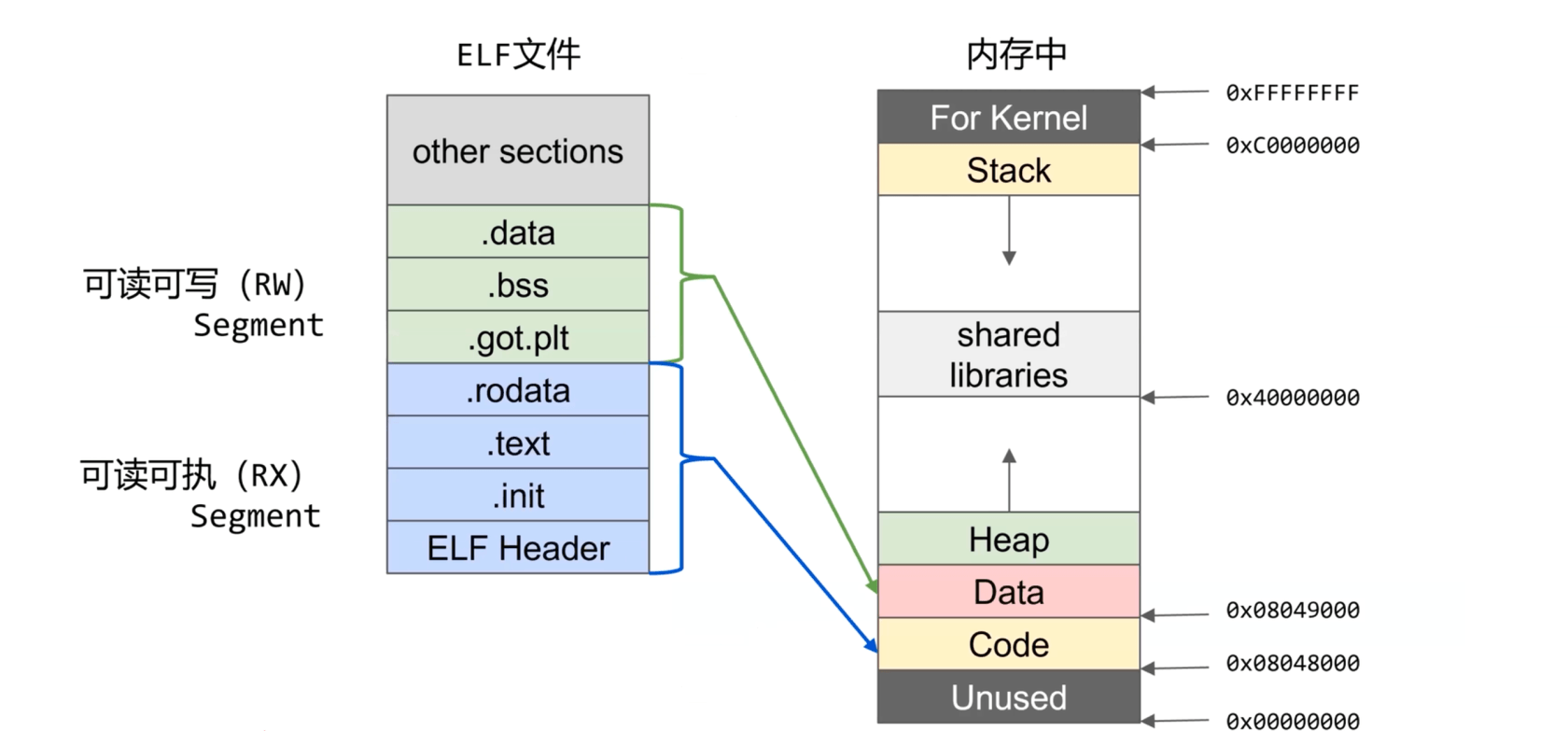
段表结构
PE(Windows 可执行文件)
| IDA 段名 | PE 节名 (Section) | 运行时内存映射 / 权限 | 主要作用 / 内容说明 |
|---|---|---|---|
.text |
.text |
RX(可执行、只读) | 程序主代码区,函数体、指令、跳转表。 |
.rdata |
.rdata |
R(只读) | 常量字符串、浮点常数、导入/导出表的辅助结构。 |
.data |
.data |
RW(可读写) | 已初始化的全局变量、静态变量。如:int a = 10; |
.bss(有时合并在 .data) |
.bss |
RW(可读写) | 未初始化的全局变量、静态变量,加载时系统将其自动置零。如:int a |
.idata |
.idata |
R(只读) | Import Address Table (IAT)、Import Name Table,DLL导入信息。 |
.edata |
.edata |
R(只读) | Export Table,程序导出符号、函数名、导出地址。 |
.reloc |
.reloc |
R(只读) | 重定位信息表(IMAGE_BASE_RELOCATION),ASLR 时修正地址。 |
.rsrc |
.rsrc |
R(只读) | 程序资源(图标、菜单、对话框、版本信息等)。 |
.pdata |
.pdata |
R(只读) | 异常处理、函数展开信息(SEH 表)。 |
.xdata |
.xdata |
R(只读) | 对应 .pdata 的扩展异常信息表。 |
.tls |
.tls |
RW(线程本地) | Thread Local Storage,全局线程变量初始化数据。 |
.CRT$XCA ~ .CRT$XCZ |
.rdata(逻辑上属于CRT) |
R | C 运行库初始化段,用于构造函数注册。 |
.CRT$XCU |
.rdata |
R | C++ 全局对象构造函数表。 |
.CRT$XTU |
.rdata |
R | C++ 全局对象析构函数表。 |
.debug / .pdb |
.debug 或外部 .pdb |
N/A(调试信息) | 调试符号表、类型信息(DWARF 或 MS CodeView 格式)。 |
.textbss(少见) |
.textbss |
RWX | 某些驱动或压缩壳工具临时可执行读写区。 |
.cfg / .sxdata |
.cfg, .sxdata |
R | 安全控制流 (Control Flow Guard) 与异常处理扩展信息。 |
ELF(Linux/Unix 可执行文件)
| IDA 段名 | ELF 节名 (Section) | 运行时映射 / 权限 | 主要作用 / 内容说明 |
|---|---|---|---|
.text |
.text |
RX(可执行、只读) | 主代码段(函数、指令)。 |
.rodata |
.rodata |
R(只读) | 只读数据:字符串常量、浮点常数。 |
.data |
.data |
RW(可读写) | 已初始化的全局/静态变量。如:int a = 10; |
.bss |
.bss |
RW(可读写,零填充) | 未初始化的全局/静态变量。如:int a |
.init |
.init |
RX | 程序启动时执行的初始化函数(编译器插入)。 |
.fini |
.fini |
RX | 程序退出时执行的析构函数。 |
.init_array |
.init_array |
R | 全局构造函数指针数组(C++构造)。 |
.fini_array |
.fini_array |
R | 全局析构函数指针数组(C++析构)。 |
.ctors / .dtors |
.ctors, .dtors |
R | 老版 GCC 构造/析构函数表(被 init_array/fini_array 替代)。 |
.plt |
.plt |
RX | 程序链接表 (Procedure Linkage Table),PLT 表中只存放 GOT 表项的地址,而不是函数真实的地址,函数真实的地址存放在 GOT 表中。 |
.got |
.got |
RW | Global 全局偏移表 (Global Offset Table),保存动态解析后的函数地址。 |
.got.plt |
.got.plt |
RW | 明确划分给 PLT 使用的 GOT 条目。 |
.rel.plt / .rela.plt |
.rel.plt / .rela.plt |
R | 动态链接重定位信息(针对 PLT)。 |
.dynamic |
.dynamic |
R | 动态链接器使用的动态段信息表(lib, rel, strtab等指针)。 |
.dynsym |
.dynsym |
R | 动态符号表(导入导出函数符号)。 |
.dynstr |
.dynstr |
R | 动态字符串表,对应 .dynsym 中名字索引。 |
.symtab |
.symtab |
R | 完整符号表(仅调试可见)。 |
.strtab |
.strtab |
R | 对应 .symtab 的字符串表。 |
.eh_frame |
.eh_frame |
R | 异常处理帧信息(C++ 异常栈展开)。 |
.gcc_except_table |
.gcc_except_table |
R | GCC 异常表,支持 C++ try/catch。 |
.interp |
.interp |
R | 指定 ELF 运行所需的动态加载器路径(如 /lib64/ld-linux-x86-64.so.2)。 |
.note.ABI-tag / .note.gnu.build-id |
.note.* |
R | 元数据、构建ID、ABI标识。 |
.debug_* |
.debug_info, .debug_line, .debug_abbrev 等 |
N/A(调试) | DWARF 调试信息。 |
.comment |
.comment |
R | 编译器版本等注释信息。 |
ida使用
IDA中的一些数据类型
| 类型类别 | ILP32 (32-bit) | LP64 (Unix x86_64) | LLP64 (Windows x64) |
|---|---|---|---|
char |
1 | 1 | 1 |
short |
2 | 2 | 2 |
int |
4 | 4 | 4 |
long |
4 | 8 | 4 |
long long |
8 | 8 | 8 |
pointer (void*) |
4 | 8 | 8 |
size_t |
4 | 8 | 8 |
ssize_t |
4 | 8 | 8 |
ptrdiff_t |
4 | 8 | 8 |
intptr_t / uintptr_t |
4 | 8 | 8 |
IDA 中的宏
宏只是帮助反映汇编寄存器或变量的「高/低部分」,在真实的 C 源码里是不存在的
| 名称 | 含义 | 取的是什么 | 位宽 |
|---|---|---|---|
LOBYTE(x) |
Low Byte | 取低 8 位 | 1 字节 |
LOWORD(x) |
Low Word | 取低 16 位 | 2 字节 |
LODWORD(x) |
Low Double Word | 取低 32 位 | 4 字节 |
HIBYTE(x) |
High Byte | 取高 8 位 | 1 字节 |
HIWORD(x) |
High Word | 取高 16 位 | 2 字节 |
HIDWORD(x) |
High Double Word | 取高 32 位 | 4 字节 |
ida各页面内容【在菜单View的open subview】
1.Hex View页面:直接查看程序的二进制内容(以hex值表示)
2.Function name:函数表用于分析每一个单独的函数
3.strings:字符串表 包括程序中存储的字符串常量
4.import export :导入表和导出表,表中内容为程序需要的外表函数和可以被外部程序调用的函数
5.segments :包程序的各个段的信息
.text — 代码段(可执行),存放函数、指令。
.rdata — 只读数据,常量字符串、只读表。
.data — 可读写数据(全局变量)。
.idata — Import table(导入表)。
.bss — 未初始化数据(仅占虚拟地址空间)。
.reloc — 重定位表(如果存在)。
.rsrc — 资源(Windows 可执行文件)
.CRT - 运行时/CRT初始化数据(__main 等)
.tls - 线程局部存储
6.IDA-View窗口(反汇编窗口)
快捷键总结
F系列【主要是调试状态的处理】
F2 添加/删除断点
F4 运行到光标所在位置
F5 反汇编【常用】
F7 单步步入
F8 单步跳过
F9 持续运行直到输入/断点/结束
shift系列【主要是调出对应的页面】
shift+F1 Local types(结构体) 【常用】
shift+F2 execute scripts
shift+F3 Functions
shift+F4 Names
shift+F5 Signatures
shift+F7 Segments
shift+F8 Segments registers
shift+F9 Structures
shift+F10 Enumerations
shift+F11 Type libraries
shift+F12 Strings(全局字符串) 【常用】
Shift+E 导出数据段中的数据(多种形式可以选择)【常用】
单字符系列【基本是数据处理转换相关】【这些都比较常用】
G 按地址查找
R 单个数字转换成对应的字符串【常用】
D 把选中字节当作数据【常用于地址显示,指令分解】
N 重命名(函数名、变量名等)【常用】
Y 修改变量类型等(比如int改char等等)
H decimal 数据的进制快速转换
A 把选中区域识别为字符串【常用】
C code(将数据转变为汇编代码)
U undefined(取消定义,将字符串或者函数转变为原始数据)
X 交叉引用(反汇编页面选中函数查找引用,汇编文本页面选中变量查找引用)【常用】
P 选中位置识别为函数起点【常用】
Ctrl、Alt系列
Ctrl+F 搜索【常用】
Ctrl+X 交叉引用(汇编页面)【常用】
Alt+T 查找Text
Ctrl+T 查找下一个text
Alt+C Next Code
Ctrl+D Next Data
Ctrl+Z 撤销
Ctrl+N 快速NOP
Ctrl+S 跳转到任意段
Ctrl+Shift+Z 恢复
Alt+K 修改堆栈值
其他
右键 → Hide casts 隐藏的编译器在反编译页面的自动插入【常用】
tab 伪代码页面和汇编页面的切换【常用】
空格 文本模式和普通汇编页面的切换【常用】
patch
选中要修改的内容, Edit → Patch program → Assemble
Edit → Patch program → Apply patches to input file,导出修改后的程序
解方程神器z3的使用
示例1—一个最简单的解方程
1 | from z3 import * |
示例2—有位运算,答案是字符串,结果不唯一的解方程
题目
1 | for (i = 0; i <= 33; ++i) { |
解
1 | from z3 import * |
花指令总结
花指令就是往代码里添加一些数据,虽然不会影响程序的正常运行,但是会使你的ida 在生成汇编代码时出错
不可执行花指令
这类花指令是很好理解的,ida编译的时,遇到分支指令或者跳转指令时不会跳转。也就是说一些永远不会执行的分支里的数据,也会被当作代码执行,如果我们在这些分支里编写错误的数据,ida编译就会报错
比如jmp跳转,或者跳转的位置无论如何都不变,这时分支里的数据就是无用的
例如jmp short near ptr loc_40102E+1,那么代码标签loc_40102E的第一个字节就应该改成90(nop),因为ida会把这个字节当作操作数,导致报错
可执行花指令
如果反编译器检测到指令破坏了堆栈平衡,即函数返回时与调用时堆栈状态发生了变化,就会报错
在函数内出现了:
多余的 push 没有对应的 pop
手动修改了 esp 或 ebp
ret 前栈没有恢复到进入函数时的状态
就有可能报错
1 | ...:00815023 038 E8 00 00 00 00 call $+5 ;压入call 的下一条指令的地址,即0x815028 |
简单的脱壳
ESP 定律
壳 是在一些计算机软件里也有一段专门负责保护软件不被非法修改或反编译的程序。
它们一般都是先于程序运行,而不是修改源代码
加壳程序初始化时保存各寄存器的值,外壳执行完毕,恢复各寄存器值,最后再跳到原程序执行
通常用 pushad / popad、pushfd / popfd 指令对来保存和恢复现场环境
ESP 定律就是在push后对ESP进行断点,然后执行到断点获取到源程序的入口