前言
个人感觉pwn和web是安全俩个大方向,与逆向相比,pwn要更加底层,所以暂时并不打算过于深入的学习pwn,旨在了解一些简单的二进制漏洞即可
感觉pwn比逆向难学多了,诶,慢慢来吧,着急不得,这里暂时先把那几个常见漏洞的原理,常见利用,和加固了解一下,学的太艰难了
常见pwn工具的使用
GDB 的使用方法
GDB(GNU Debugger)是 Linux/Unix 系统中常用的程序调试工具
1 | gdb 文件名 #调试可执行文件 |
Pwntools 的使用
checksec
检查安全机制开启情况
1 | RELRO: Partial RELRO #Partial RELRO:.got不可写,got.plt可写 |
ROPgadget
ROPgadget常用于寻找一些可以被利用的汇编代码段,Ret2syscall找链子就是用的这个工具
1 | ROPgadget --binary 文件名 --string '/bin/sh' #获取字符串地址 |
编写攻击脚本
1 |
|
struct 在脚本编写中的使用
struct 模块可以将某些特定的结构体类型打包成二进制流的字符串
pwntools 里的 p32 / p64 本质就是 struct 的封装。
1 | #打包 |
| 类型 | struct 格式 | 字节 | pwntools |
|---|---|---|---|
| uint8 | B | 1 | p8 |
| uint16 | H | 2 | p16 |
| uint32 | I | 4 | p32 |
| uint64 | Q | 8 | p64 |
| float | f | 4 | 无(需 struct.pack) |
| double | d | 8 | 无(需 struct.pack) |
ctypes 在脚本编写中的使用
因为我们编写环境是python有的时候需要使用到c的函数
ctypes 在 Python 中 加载和调用 C 动态库。实现在python环境中调用c函数
1 | from ctypes import * |
常见二进制普适漏洞及利⽤
栈缓冲区溢出
栈溢出指的是程序向栈中的某个变量写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。
基础知识
栈是汇编程序中用于管理函数调用、参数传递、局部变量和寄存器状态的内存结构。
它让程序能像积木一样层层调用又安全返回,是 CPU 调用机制的“中枢神经”。
sp——stack point——堆栈指针寄存器,始终指向当前栈顶,是push和pop的参考坐标
bp——base point——基础指针,在函数执行期间固定,作为当前函数栈帧的基准点
栈具有高地址在上,低地址在下的特点,即老数据在大地址,新数据在小地址,pop的时候,sp增加,push的时候sp减少
32位代码说明
1 | main: |
32位栈位大小位4字节
1 | ↑ |
函数的调用与返回是对称的:
进栈多少字节,就要出栈多少字节。
sink点
gets函数
gets函数是一个危险函数。因为它不检查输入的字符串长度,而是以回车来判断结束
1 | int __fastcall main(int argc, const char **argv, const char **envp) |
如上述代码输入超过 15 字节,就会覆盖s 后面的栈空间,而s是main函数中的临时变量,后紧跟saved RBP和return address,溢出就会覆盖返回地址
strcpy函数
1 | char s[32]; // 栈上的固定大小缓冲区 |
read函数
1 | ssize_t vulnerable_function() |
ret2text
ret2text 即控制程序执行程序本身已有的的代码(.text)。即存在危险函数如system或execv,可以直接劫持返回地址到目标函数地址上
如何利用后门函数
直接调用函数
可以直接调用,但是64 位系统高版本需要在调用前函数前加个ret平衡堆栈,glibc2.27 以后引入 xmm 寄存器,记录程序状态,在执行 system() 函数时会执行 movaps 指令,要求 rsp 按 16 字节对齐,需要在进入 system() 函数之前加上一个 ret 指令的地址来平衡堆栈
1 | from pwn import * |
为什么加个ret就能平衡堆栈哪?加ret难道不会影响后面的函数跳转吗?
比如说注入点是gets函数,注入完成之后函数返回
1 | ; 函数返回(epilogue) |
因为返回地址是ret,所以RIP为当前插入的ret的地址,rsp指向栈中的fuc_addr
此时再执行一次ret,RIP为当前插入的fuc_addr的地址
所以等于说加个ret,调用结果没有变但是RSP += 8
为什么需要RSP += 8?
函数内容如下
1 | .text:0000000000401186 push rbp |
可以看到函数执行的时候,会先push rbp,此时RSP -= 8
调用system方法
其实我们只要保证lea rdi, command call _system这两行汇编代码执行就行了,所以我们可以选择p64(40118A)或者p64(401187)作为调用地址,只要不执行push rbp,就不需要ret
没有system(“/bin/sh”),但可以自己构造
程序存在system函数,但是程序没有调用system("/bin/sh"),这个时候我们自己调用该函数实现利用
32位构造
当正常调用 system() 函数的时候,push bin_sh_addr call system_addr
esp会指向返回地址,而system函数的传入参数紧跟其后,所以我们system_addr后需要加一个虚假的返回地址
这里的 b’aaaa’ 其实是填充一个 4 字节的数据,写成 p32(0) 或者 p32(0xdeadbeef) 也是一样的
1 | # 没有system("/bin/sh"),但可以自己构造 |
64位构造
64 位程序优先使用寄存器来传递参数,前 6 个参数是通过寄存器(RDI、RSI、RDX、RCX、R8、R9)传递的,多余的参数才通过栈传递
这里pop rdi会取出bin_sh_addr存入rdi,然后ret调用system_addr
1 | # 没有system("/bin/sh"),但可以自己构造 |
ret2shellcode
程序存在溢出,并且还要能够控制返回地址,但是并没有现成的system函数供我们调用,此时如果存在bss变量可控,并且该变量所属段可写可执行,我们就可以自己填充shellcode 引导程序执行触发
使用 gdb 调试查看bss段是否有可执行的权限
1 | gdb ret2shellcode #使用gdb |
需要注意的是Ubuntu 20及以后的系统,即使程序没有启用 NX 和 ASLR,且程序设置了bss段可执行,但是系统还是会把BSS 段和数据段也不会被标记为可执行。注意题目中的系统版本,并且本地测试使用Ubuntu 18及以下版本系统
1 | from pwn import * |
如果没有给现成的写入shell方法,但是程序有read函数,可以调用read函数写shell了
1 | payload=b'a'*(0x38)+p32(read_addr) |
Ret2syscall
Ret2syscall 可用于绕过沙箱保护,或者针对静态编译等没有 libc 的场景
调用分为两种一种是函数调用,和我们自定义的函数本质上没有什么区别,绝大多数函数(如 strcpy、gets、printf、fgets、memcpy、strlen、system)都不是系统调用,但是libc函数实现可能是系统调用的用户态封装
还有一种是系统调用,和我们自定义的函数不同的是,系统调用函数通过系统调用号来调用函数,如read、write、open、execve等
系统调用的调用方法
1 | ;32位系统调用函数的调用方法 |
和我们前面学汇编的输入输出调用方法很像,突出一个方便快捷
Ret2syscall的原理就是如果栈溢出没有system函数,我们可以控制程序执行系统调用获取 shell,如构造系统调用:execve("/bin/sh", 0, 0)
利用条件:需要有四个寄存器的pop|ret和int 0x80|syscall
32位execve执行
1 | payload = b'a' * (0x20 + 0x4) |
64位execve执行
1 | payload = b'a' * (0x20 + 0x8) |
Ret2libc
适用于程序中没有 system() 函数和 “/bin/sh”,或者程序开启了 PIE 地址随机化,需要泄露程序运行时的地址来计算偏移地址
动态链接
静态链接是将编译期将所有库代码直接拷贝进可执行文件
动态链接,系统会将常见的函数放在libc.so动态链接库中,程序运行时需要调用哪个函数就从 libc.so库中找
动态链接相比静态链接更加节省内存、磁盘空间,并且调用起来更加灵活,方便对系统模块进行扩展兼容
那么动态链接是怎么做到的那?
GOT
GOT 位于 .got / .got.plt 段,本质是一个 指针数组
.got 存放的是“作为数据被使用的地址”,包括全局变量地址、函数指针、vtable 等;
.got.plt 只服务于“通过 PLT 调用的函数”,保存真实的函数地址
PLT
为什么需要PLT?
程序代码段是 只读(RX),不能在代码中直接修改 call 目标,所以我们需要一个中转指针去映射GOT表
即call → PLT
PLT → 查 GOT
GOT → 真函数
延迟绑定
延迟绑定其实指的就是动态链接的实现过程
初始情况下puts@plt和puts@got相互指引
.got.plt 初始值指向 plt+6,第一次执行 PLT 时跳过间接跳转,进入负责延迟绑定的指令序列;
动态链接需要在运行时填 GOT,第一次访问puts@plt时,动态链接器就会去动态共享模块中查找 puts函数的真实地址然后将真实地址保存到puts@got中(.got.plt);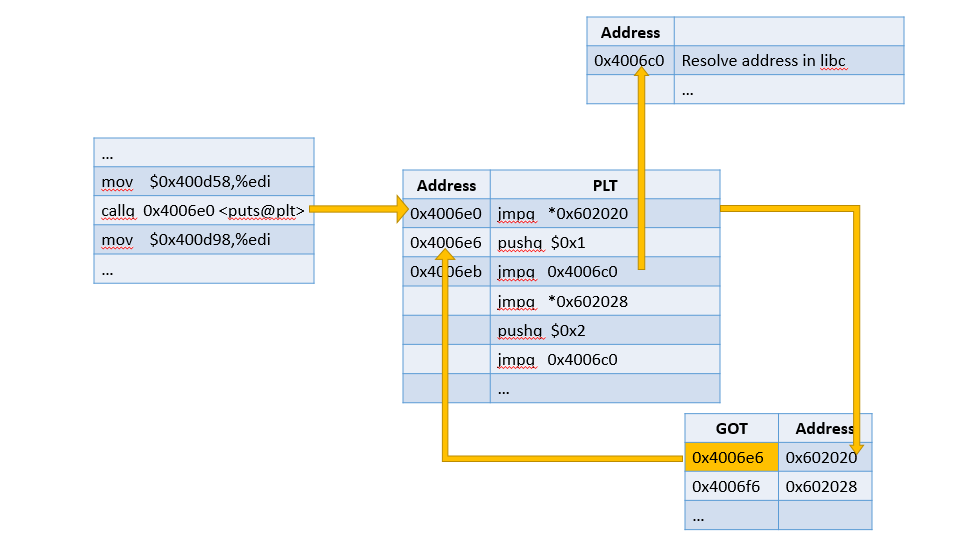
第二次访问puts@plt时,就直接跳转到puts@got中去。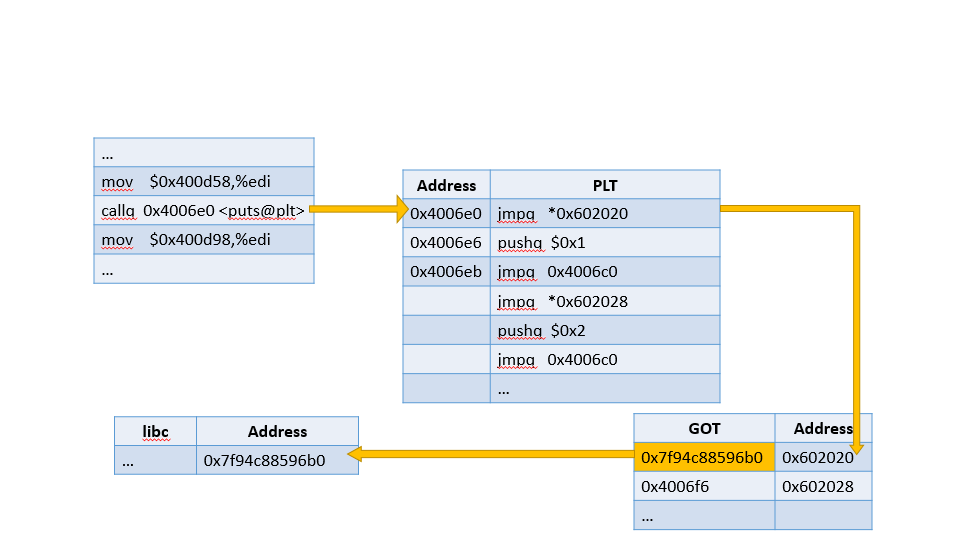
Full RELRO 的本质是:
放弃延迟绑定,在程序启动阶段一次性解析所有符号,即一开始就把got表写好,然后把 GOT 设为只读。
实例
system 函数属于 libc,而 libc.so 动态链接库中的函数之间相对偏移是固定的。所以我们只要得到libc的版本,就可以知道了system函数和/bin/sh的偏移量。知道偏移量后,再找到libc的基地址,就可以得到system函数的真实地址
libc基地址 + 函数偏移量 = 函数真实地址
首先需要泄露出一个函数的真实地址
由于 libc 的延迟绑定机制,我们可以泄漏已经执行过的函数的地址
实例一32位通过write泄露read的真实地址
1 | io = remote("node4.buuoj.cn", 25051) |
实例二64位通过puts泄露puts的真实地址
1 | puts_plt = elf.plt['puts'] |
通过泄露出的got地址计算出libc中的system和/bin/sh的地址
如果已知 libc 可直接使用
1 | libc = ELF("libc路径") |
如果未知则使用 LibcSearcher,需要确定 libc 版本
1 | from LibcSearcher import * |
绕过 Canary
基础知识
在程序的函数入口处中保存一个随机值(canary),溢出覆盖返回地址前必须先覆盖 canary;程序在返回时检测 canary 是否改变,若改变则触发异常。
Canary是从线程中获取的,每次进程重启的 Canary 都不同,无法静态获取,十六进制通常以 ‘\x00’ 结尾,例如:0x29a30f00。在同一次运行中,Canary 的值是不会变的,并且同一个进程中的不同线程的 Canary 是相同的,通过 fork 函数创建的子进程的 Canary 也是相同的
canary在ida中的表现形式
一般放在函数开头位置
在 64 位程序中,表示从 FS 段寄存器指向的线程本地存储(TLS)中读取一个 8 字节(QWORD)数据,通常为 FS:28hv2 = __readfsqword(0x28u);
在 32 位程序中,表示从 GS 段寄存器指向的线程本地存储(TLS)中读取一个 4 字节(DWORD)数据,通常为 GS:14hv2 = __readgsdword(0x14u);
通常 Canary 在栈中是位于 RBP 上方的 8 字节(与 RBP 相邻),但是 Canary 的位置不一定总是与 RBP 相邻
具体需要看变量v2的位置,变量v2的位置就是carry在栈中的位置
栈迁移
最简单的实例
1 | v3 = __readfsqword(0x28u); |
puts会一直打印直到遇到\x00,通过 puts 可泄露 Canary
然后在第二次循环的时候填充正确的 canary即可绕过canary机制
1 | pay = b'A' * 0x38 + b'^'#小端排序下Canary 的 最高字节是 \x00,需要覆盖 |
格式化字符串漏洞
在调用printf函数时, printf() 会严格的按照 format 参数所规定的格式逐个从栈中取出并输出参数,如果没有给出传参或者传入参数小于format 参数,就会开始依次打印栈中的数据
64位系统程序会先打印RDI,RSI,RDX,RCX,R8,R9,如果参数超过6个才将栈上地址视为参数地址
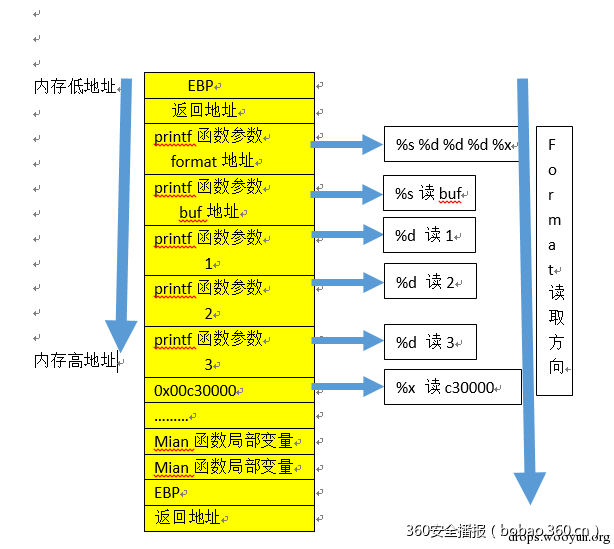
覆盖栈内存
而printf() 将出现在 %n 之前的字符数量存储到对应的参数所指向的变量中,根据这个设定配合$位置参数,我们就可以实现任意可写数据修改
漏洞代码
1 | int c = 789; |
s是可控的我们想要修改c为16,
首先我们需要找到我们传入的s的值,存储在栈的什么地方
1 | from pwn import* |
可见在打印第11个传参时,开始出现我们传入的AAAA(0x41414141),所以我们可以确认第11个参数是可控的
%11$n,就是把第11个参数当成指针地址,并计算之前输出的字符数存储到指针所指的位置
1 | from pwn import * |
这里第11个参数就是我们传入的c变量的地址,需要凑够16个字符,就可以更改c为16了
pwntools对这个利用有封装payload=fmtstr_payload(11, {x_addr:16})
泄露任意地址内存
上面是利用printf() 的 %n特性实现了变量修改
而printf() 的 %s可以获取一个指针对应的值
所以我们确定可控参数后就可以泄露任意地址对应的值
1 | from pwn import * |
字符串 \0 截断
凡是 C 字符串函数,无一例外都会被 \0 截断,如\0可截断strlen绕过检查,strncpy被截断后会补0。这是c底层设计,大二的时候我们写汇编代码的时候字符串也是要求必须以\00结尾,不然会连读
但是c的内存操作函数,如memcpy就不会出现字符串 \0 截断
伪随机数
c的随机数rand和php随机数函数mt_rand()一样都是伪随机数,只要种子一样,生成的数字序列也一样